How I outperformed BuiltWith and PublicWWW’s free plans with a couple hours and 30 lines of code.
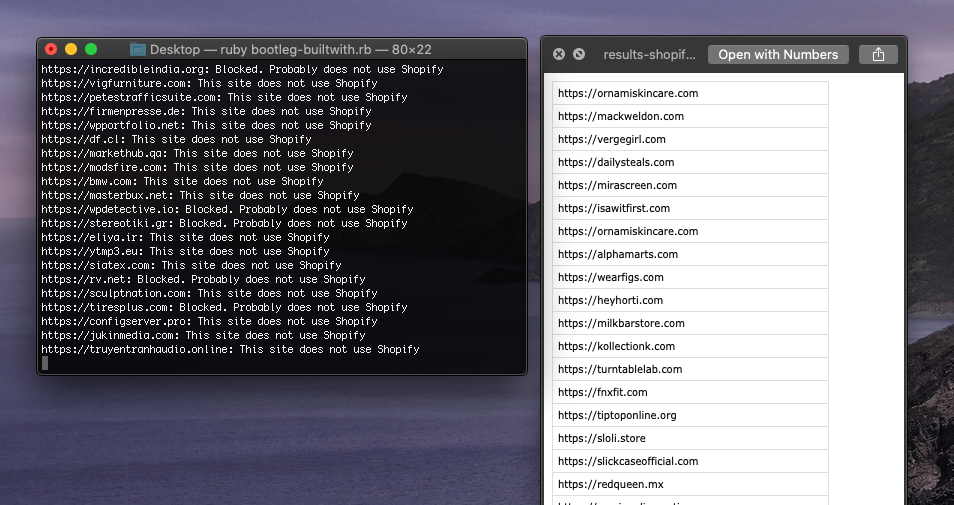
What if you wanted to find a list of websites that are using a specific piece of technology? Like if you wanted a list of all websites using WordPress? Or in my case, all websites built with Shopify?
You might turn to BuiltWith or PublicWWW. These sites scan the source code of websites to determine the technology the website is built on.
Very useful and cool. Until you see the pricing pages:
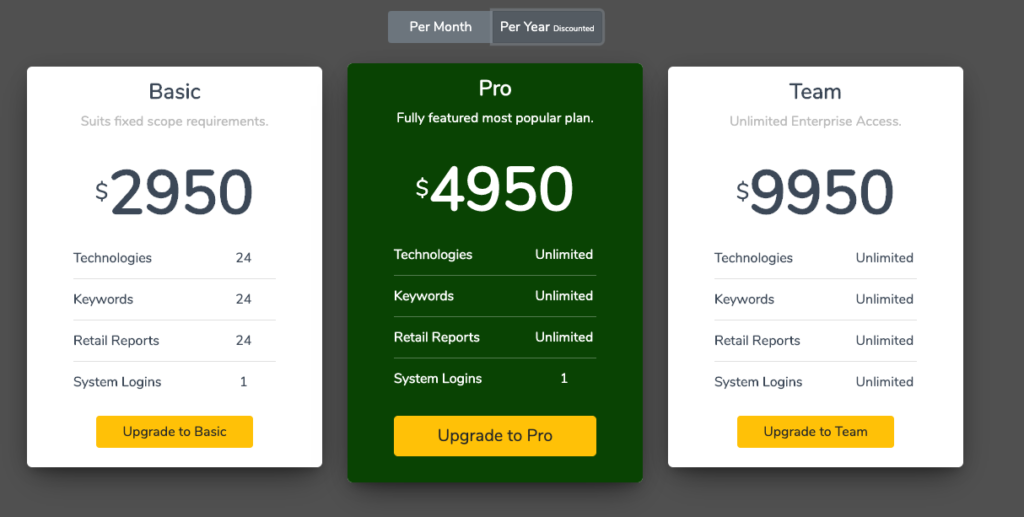
Now, let me just say – I get it.
The work they’re doing ain’t easy, and the pricing is justifiable, but since I can code, how about I just build my own for free?
The way I see it, this problem has two components:
- I need a script that can automatically check, when supplied a website domain, if that website is using Shopify or not.
- I need a really big list of website domains to run the first script against.
Once I have both of those pieces, I can put them together to make my Bootleg Builtwith.
Part 1: Determining if a certain website uses Shopify
Let’s start with the first component: When given a website URL, I need a reliable method to check if that website uses Shopify.
The simplest way to check if a website is using Shopify is to inspect the website source, and look for code that only a Shopify store would use.
Now, I already know of such a snippet that is unique to Shopify stores: It’s ‘trekkie’ – which is what Shopify calls their custom analytics solution:
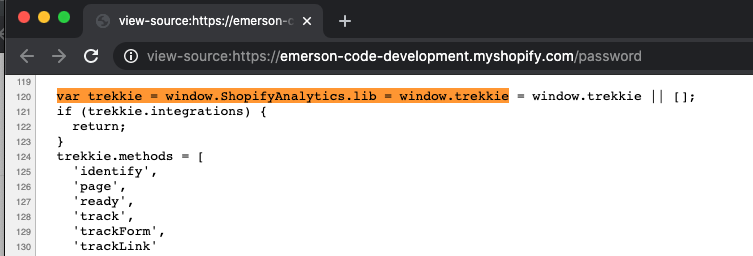
Cool. Let’s use that as a base point and start coding.
Let’s write a dead simple, 15 line, Ruby script to kick this off:
#~/desktop/is-shopify-store.rb
require 'open-uri'
# Prompt me for a URL
puts "What URL do you want to check?"
url = gets.chomp
# Open the URL I supplied above
html = open(url).read
# Checks the source code for the Shopify specific code snippet
if html.include? "var trekkie = window.ShopifyAnalytics.lib"
puts 'This site uses Shopify'
else
puts 'This site does not use Shopify'
end
Cool. Let’s run it, and try testing it against a couple websites to make sure it’s reliable:
- First test using a Shopify site => https://emerson-code-development.myshopify.com
- That worked. Let’s try a different Shopify website:
- Second test with another Shopify site => https://allbirds.com
- Once again, looking good. Now let’s try a website that definitely doesn’t use Shopify.
- Third test with a site that doesn’t use Shopify => https://amazon.com
- Error!
Ah, yes, I should’ve anticipated this but Amazon blocks my script from inspecting the website source code here.
Now I could get crazy and break out a more sophisticated scraping solution like Watir but remember this is bootleg, so let’s think through that extra work for a second…
So if Shopify stores don’t block my script, can’t I just assume that if my script is blocked, that it’s not a Shopify store? Makes sense to me. Let’s do that:
begin
html = open(url).read
if html.include? "var trekkie = window.ShopifyAnalytics.lib"
puts url + ': This site uses Shopify'
# It's a match! Let's write it to a CSV
CSV.open("/Users/emerson/Downloads/results-shopify-stores.csv", "a") do |csv|
csv << [url]
end
else
puts url + ': This site does not use Shopify'
end
rescue
puts url + ': Blocked. Probably does not use Shopify'
endOkay. Bingo. Part 1’s solution is decent enough.
Part 2: Get a big list of websites
Onto the next one: I need a massive list of domains to check.
Search engines typically use something called spiders here to find and create directories/lists of webpages. Spiders start at one webpage, follow all the links on that webpage, and then the links on those webpages, and so on until it has mapped all the webpages it can get its hands on.
Now if you wanted to build a Builtwith competitor you’d probably need to do something like that, but this is bootleg baby.
I remember Alexa.com has a list of the top million website domains or whatever. I wonder if they make the list publicly available? Surely that’d give me a lot of high ranking websites to check, and high ranked websites are what we’d prefer here anyway, right?
A quick google search revealed this Github thread with some decent leads, and from that thread I have a downloaded CSV of the ‘top million domains’.
Checking the spreadsheet, it only has 764,166 domains, not 1 million… Good enough!
Let’s start with a couple lines of Ruby code that can use a CSV spreadsheet file as an input, and loop through each domain to perform my Shopify check I outlined in part 1.
Oh yeah… the domain list only includes the URL’s base: Eg bestbuy.com, not https://www.bestbuy.com. That’s okay, let’s just assume most domains are using https:// and prepend it to the start of every URL before we check it:
url = 'https://' + urlCool. One last thing. If my script does detect a Shopify store, let’s go ahead and save that to a separate CSV to serve as my output, so when my scripts finished, I’m left with just list of websites using Shopify.
if html.include? "var trekkie = window.ShopifyAnalytics.lib"
puts url + ': This site uses Shopify'
# It's a match! Let's write it to a separate CSV
CSV.open("/Users/emerson/Downloads/results-shopify-stores.csv", "w") do |csv|
csv << [url]
end
else
...Okay… One hour later and I barely have gotten through 1000 URLs, and none of those are Shopify sites it seems.
Make sense. If you’re one of the top websites in the world, it’d make sense that you’d be using a custom platform to run it.
Given that, to make this a little bit easier, let’s go ahead and skip the first 50K top sites and start scanning at 50,001:
domainList = CSV.read('/Users/emerson/Downloads/top-1m.csv', headers:true)
domainList.drop(50000).each do |row|
url = row[1]
url = 'https://' + url
isUsingShop(url)
end
A couple minutes later and we got one!
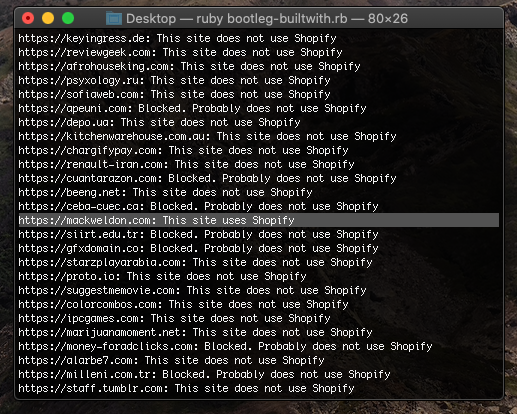
After letting that script run in the background for a few hours, I’ve checked about ~12K domains (Alexa’s top 50K-62K domains), and found ~220 of those sites are using Shopify. So 1.83% of the so far checked domains were using Shopify.
Quick and dirty math: Roughly 700K domains still need to be checked. Assuming similar positive rate as the domains I have checked so far, my bootleg script should produce a list of 10K+ high ranking Shopify stores.
Free BuiltWith: 50 high ranking Shopify stores
Free PublicWWW: 2359 high ranking Shopify stores
30 lines of Ruby code: 10K+ high ranking Shopify stores
Also, here is complete Ruby script:
require 'csv'
require 'open-uri'
def isUsingShop(url)
begin
html = open(url).read
if html.include? "var trekkie = window.ShopifyAnalytics.lib"
puts url + ': This site uses Shopify'
# It's a match! Let's write it to a CSV
CSV.open("/Users/emerson/Downloads/results-shopify-stores.csv", "a") do |csv|
csv << [url]
end
else
puts url + ': This site does not use Shopify'
end
rescue
puts url + ': Blocked. Probably does not use Shopify'
end
end
domainList = CSV.read('/Users/emerson/Downloads/top-1m.csv', headers:true)
domainList.drop(50001).each do |row|
url = row[1]
url = 'https://' + url
isUsingShop(url)
end